By A Mystery Man Writer
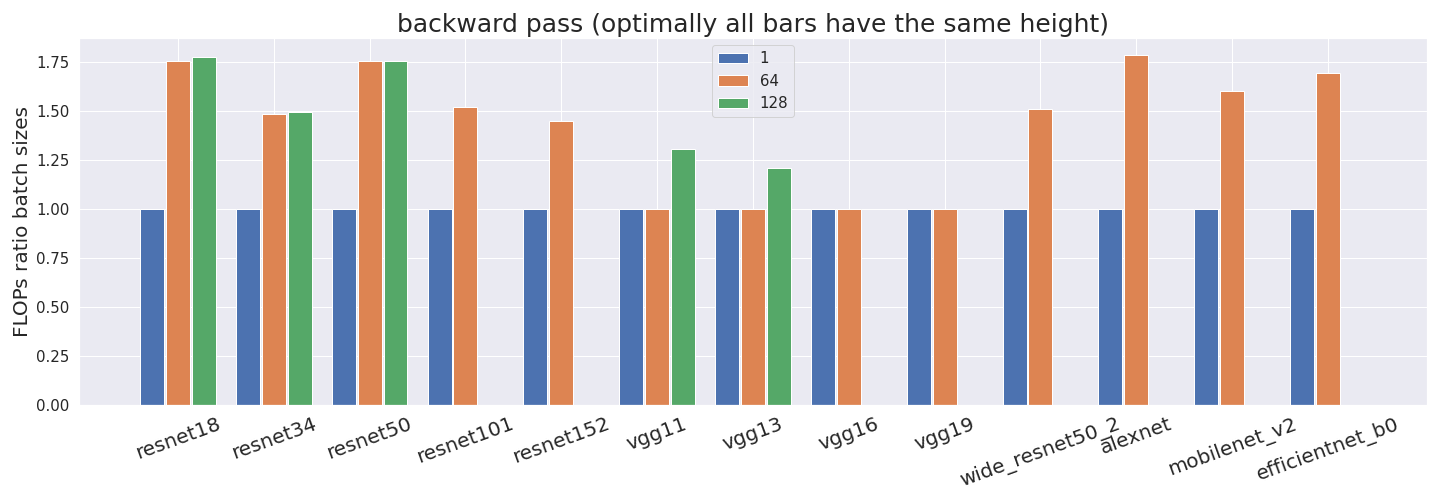
Computing the utilization rate for multiple Neural Network architectures.

The base learning rate of Batch 256 is 0.2 with poly policy (power=2).

Differentiable neural architecture learning for efficient neural networks - ScienceDirect
Review of deep learning: concepts, CNN architectures, challenges, applications, future directions, Journal of Big Data
How to measure FLOP/s for Neural Networks empirically? — LessWrong

Training error with respect to the number of epochs of gradient

Accelerating Large GPT Training with Sparse Pre-Training and Dense Fine-Tuning [Updated] - Cerebras
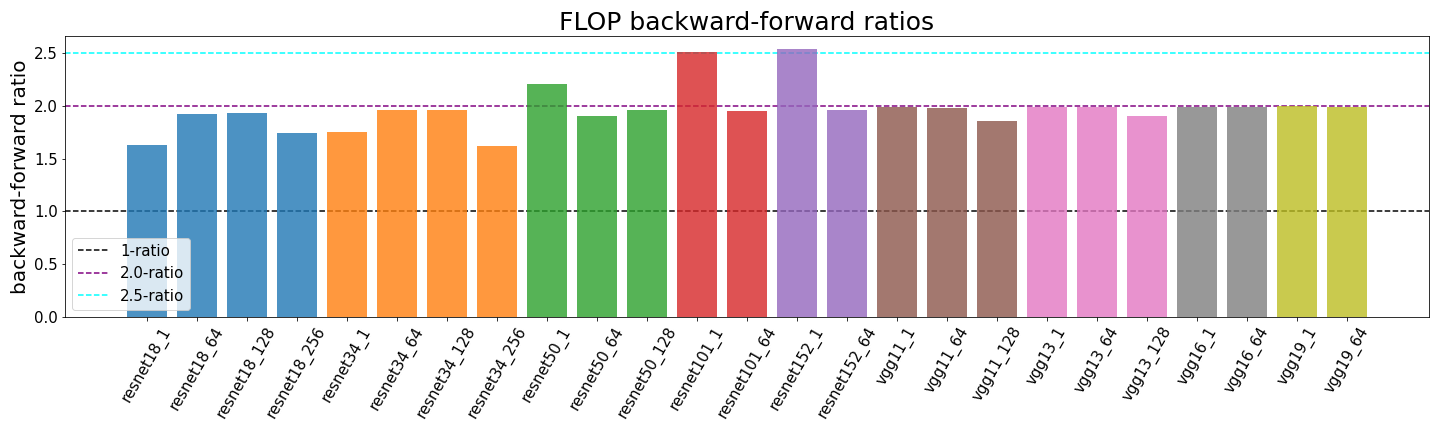
What's the Backward-Forward FLOP Ratio for Neural Networks? – Epoch
Efficient Inference in Deep Learning - Where is the Problem? - Deci
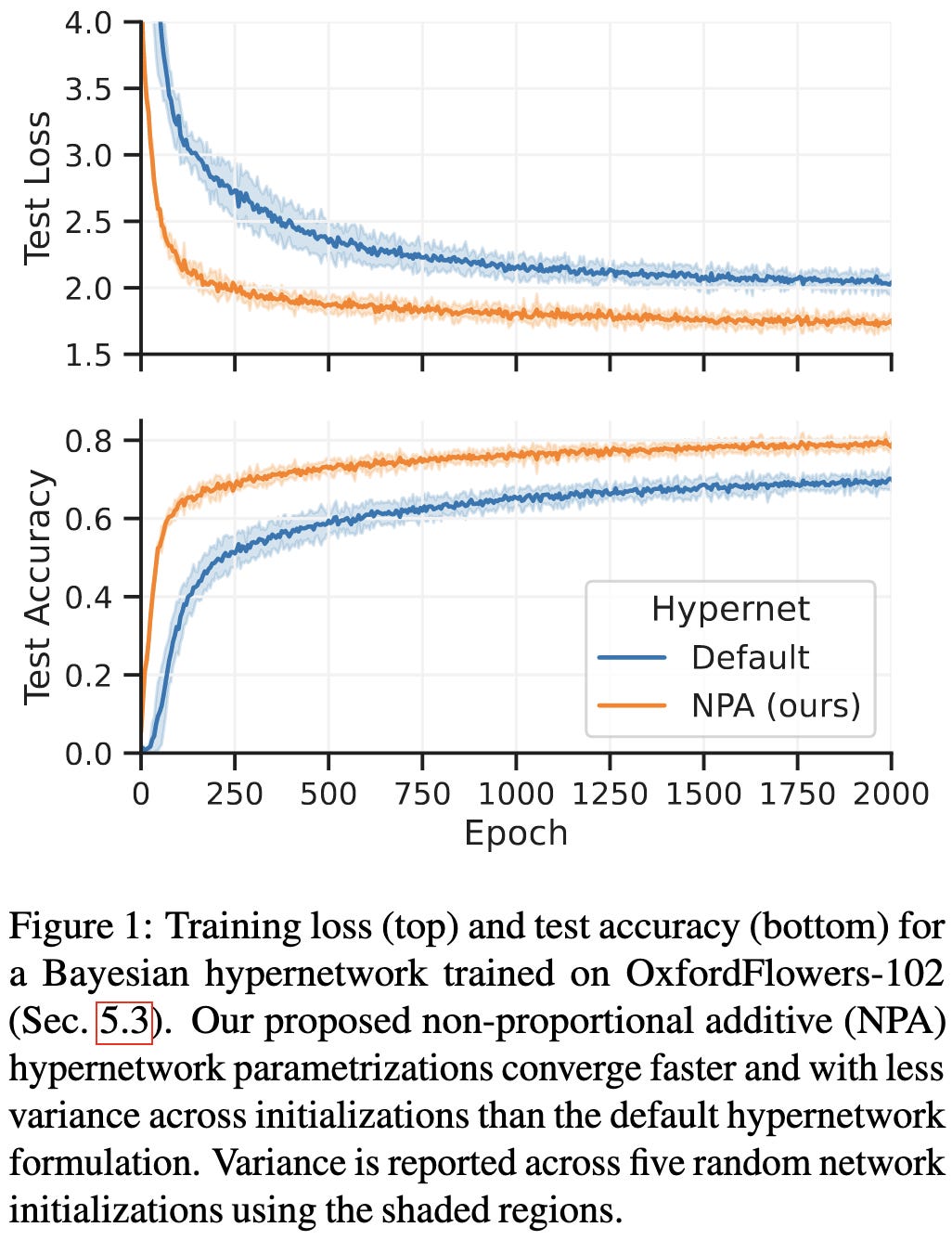
2023-4-23 arXiv roundup: Adam instability, better hypernetworks, More Branch-Train-Merge