By A Mystery Man Writer

In Spark cluster data is typically read in as 128 MB partitions which ensures even distribution of data. However, as the data is transformed (e.g. aggregated), it is possible to have significantly…

Solving Performance Bottlenecks for Spark Developers - ppt download

Stream Data from Kinesis to Databricks with Pyspark, by Himansu Sekhar, road to data engineering

How to Optimize Your Apache Spark Application with Partitions - Salesforce Engineering Blog

Cranking the Voltage on Spark: Achieve Peak Performance with Optimization, by BlackRockEngineering
Advanced Spark Tuning, Optimization, and Performance Techniques, by Garrett R Peternel

Troubleshooting Spark Challenges, PDF, Cloud Computing

Kubernetes Architecture,Hands On!, by Himansu Sekhar
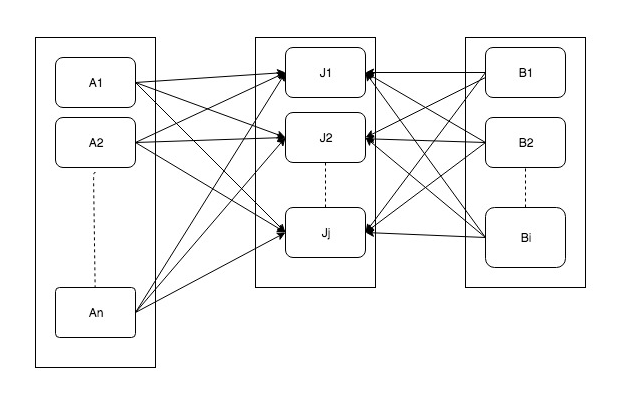
Performance Optimization of Spark-SQL
List of cool blogs focussing on Spark performance optimization., by Sukul Mahadik
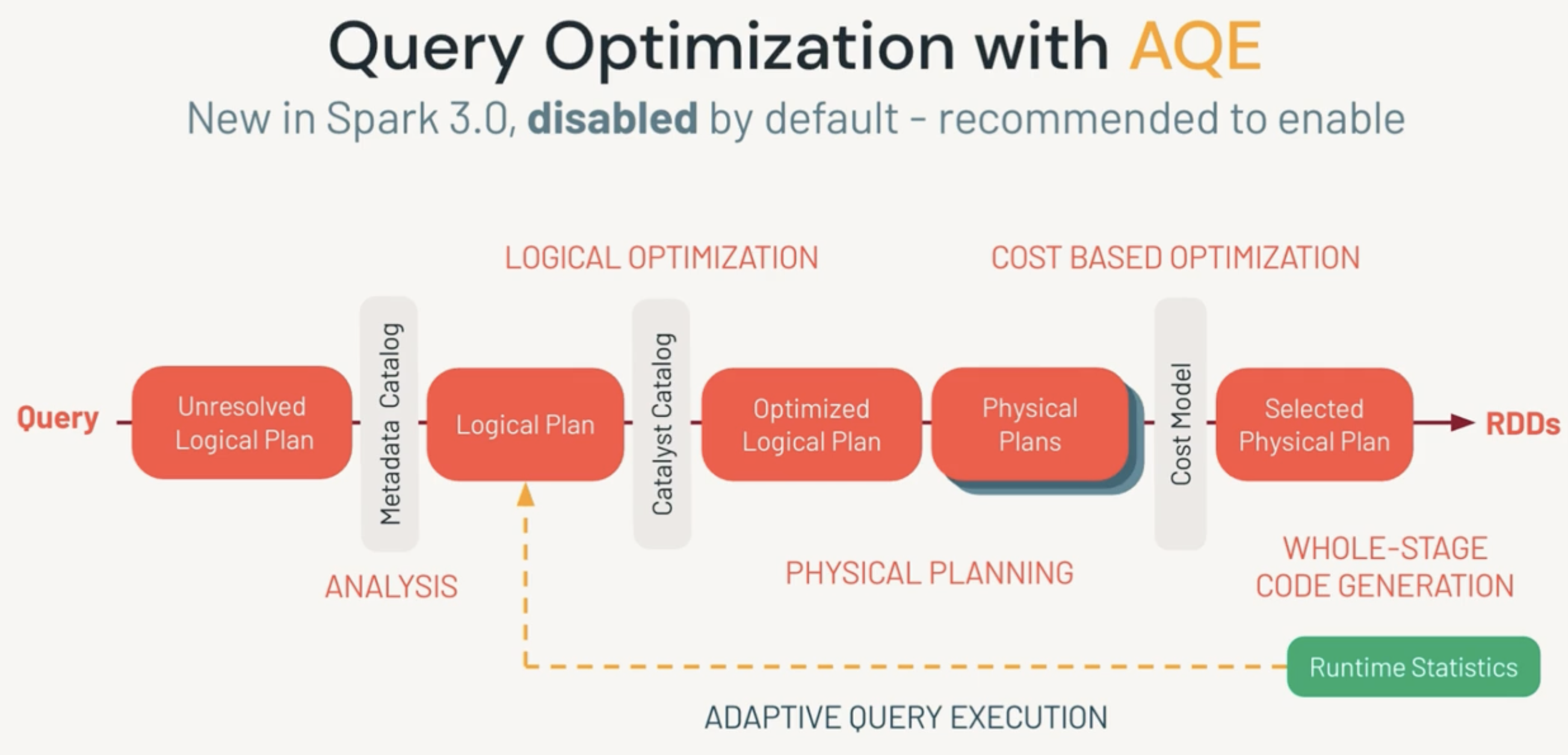
Spark working internals, and why should you care?

Apache Spark Performance is too hard. Let's make it easier

Spark Performance Tuning: Skewness Part 1, by Wasurat Soontronchai

Spark's Data Skew Odyssey: Conquering the Chaos, by Bharathkumar V